High-Performance Computing Project
Distributed-Memory Parallel Programming with MPI (C++)
Implemented MPI-based parallel programs in C++ demonstrating distributed computation, collective communication, and basic performance scaling.
What Is MPI?
A typical single-machine program has one memory space (RAM) and one CPU (possibly with many cores). As data or computational demands grow, a single machine may become too slow or run out of memory. At some point, one machine is not enough.
What if we used many computers at once? Distributed memory systems address this by using multiple machines, each with its own memory, working together. Each computer has its own memory, they cannot see each other’s RAM, and they explicitly talk to each other. This is distributed memory.
Imagine four people each have their own notebook and are working on the same problem. No one can look into anyone else’s notebook. They can only pass notes. Message Passing Interface (MPI) provides the mechanism for passing those notes.
MPI is a way for programs on different machines to talk to each other. With N copies of the same program running at the same time, each copy knows who it is (rank), how many total copies exist, and can send and receive messages.
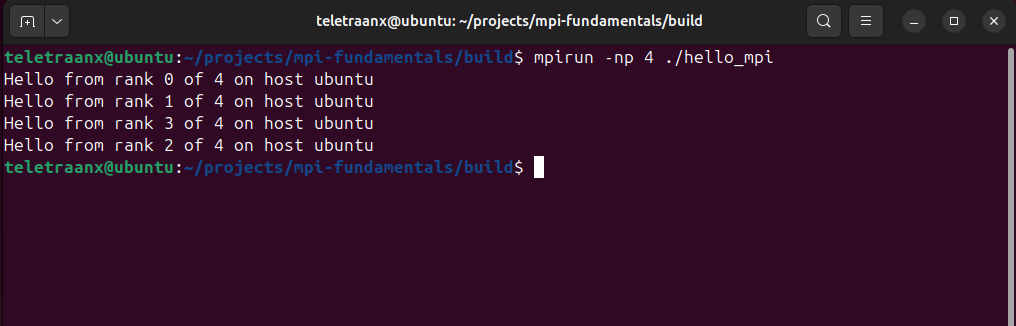
When a program is launched with mpirun -np 4 ./hello_mpi,
four independent processes are started, each executing the same code.
Program 1: Hello MPI
With this program, each process queries its unique rank and the total number of processes in the global communicator. Each rank then prints identifying information, including the hostname it is running on, illustrating how MPI coordinates parallel execution and how identical code can take on different roles across processes.
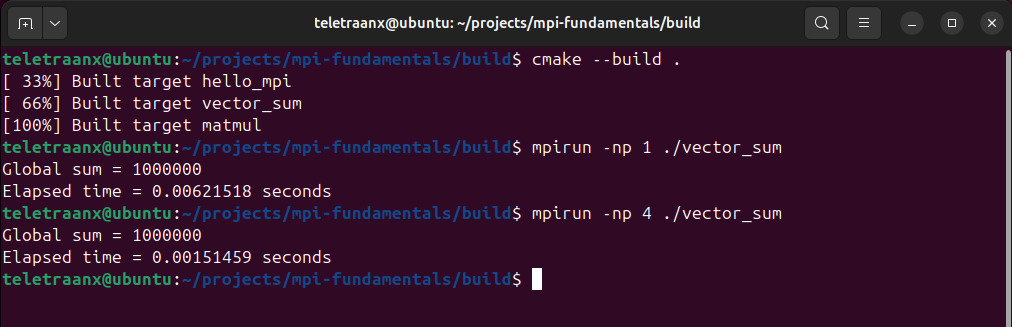
Program 2: Distributed Vector Sum
This program computes the sum of 1,000,000 integers using multiple processes. Instead of a single process performing all computation, the vector is divided across ranks so that each process allocates and sums only its local segment. Each rank computes a partial sum, then the partial sums are combined into a global result on rank 0 using MPI_Reduce with the MPI_SUM operator. The program measures execution time around the parallel region using MPI_Wtime() and MPI_Barrier().
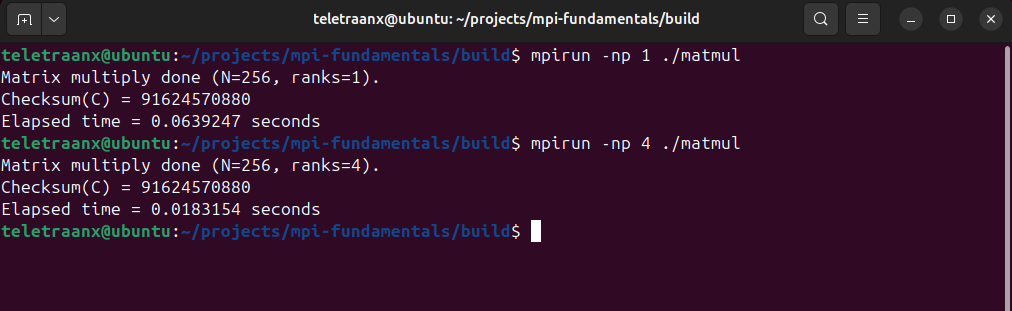
Program 3: Parallel Matrix Multiply
This program computes C = A x B for two NxN matrices (here N=256).
- Rank 0 creates full matrices A and B
- All ranks need B, so it broadcasts B to all (MPI_Bcast)
- A is split by rows across ranks using MPI_Scatter
- Each rank computes only its portion of C (its rows)
- The partial results are gathered back to rank 0 with MPI_Gather
- Rank 0 prints a checksum and elapsed time
Rank 0 initializes matrices A and B, then broadcasts B to all ranks with MPI_Bcast so each process has the full right-hand operand. Rows of A are distributed across ranks using MPI_Scatter, and each rank computes its assigned block of rows locally. The partial results are collected back to rank 0 using MPI_Gather, where a checksum is printed to verify correctness. Execution time is measured using MPI_Wtime() and MPI_Barrier().